Batch inserts e ON CONFLICT no PostgreSQL: saindo do single-row em consumers de alta frequência
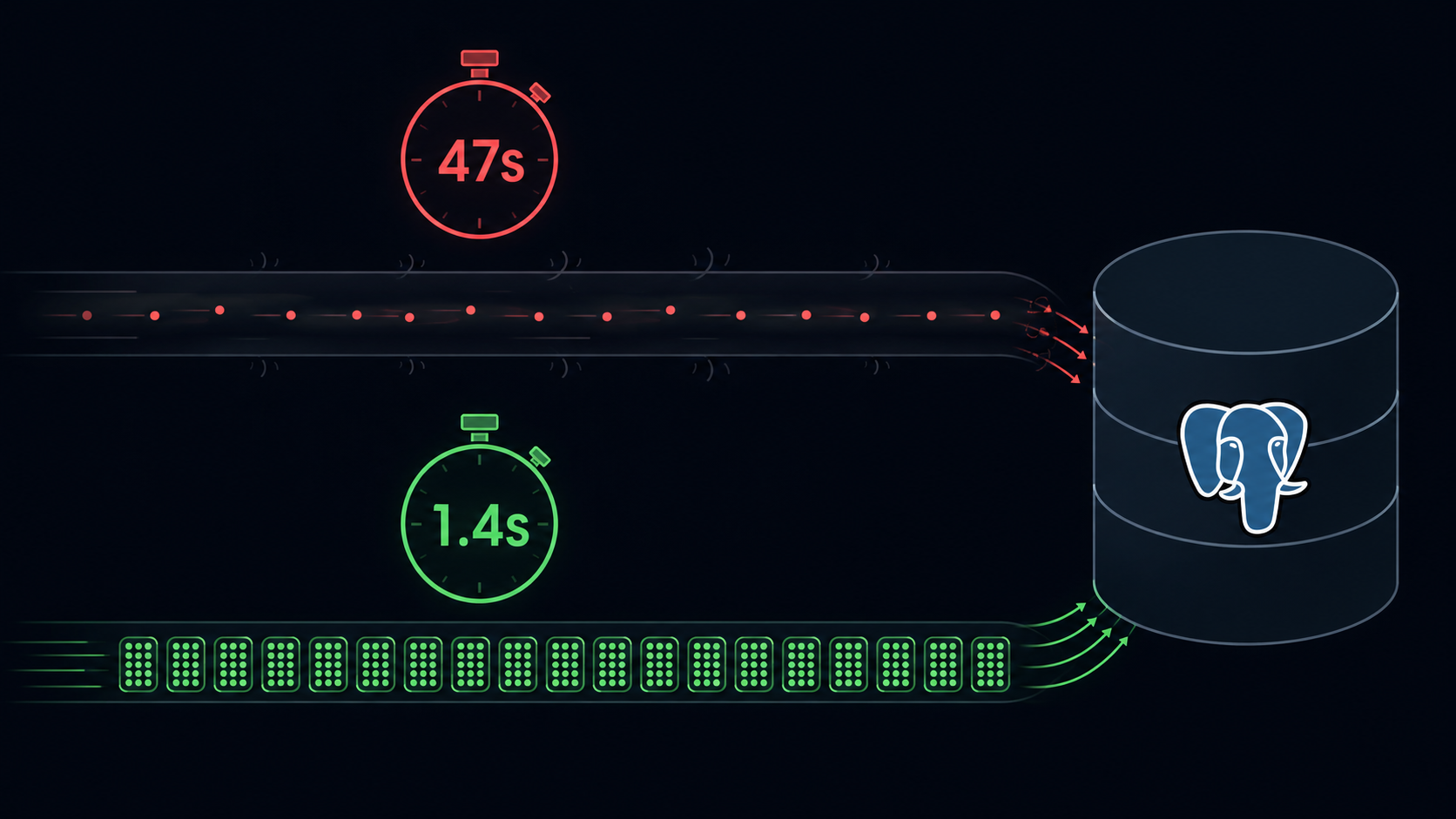
Single-row vs batch de 500: mesma carga de 10 mil eventos, mesmo schema, mesmo Aurora. 47 segundos contra 1,4.
Introdução
Um consumer que lê de fila e grava um registro por vez no PostgreSQL é um erro que só aparece quando dá errado \o/. Em baixa frequência funciona bem, é código simples e cada evento é atômico. Em alta frequência, vira o gargalo do banco inteiro.
No post anterior da série, contei de um incidente no Aurora onde um consumer que escrevia evento-a-evento estava multiplicando a carga de escrita. Aqui desço ao nível de implementação: por que isso dói, como refatorar pra batch com INSERT ... ON CONFLICT, e onde moram as armadilhas.
Pra dar tamanho ao contexto: a Harmo opera mais de 70 microservices em produção, e esse Aurora absorve na média 4.500 operações de escrita por segundo, com picos passando de 24 mil em hora cheia. Quando um único consumer dessa arquitetura grava evento-a-evento, o pedágio fixo do PostgreSQL por INSERT vira a maior parte do trabalho do banco. Single-row em alta frequência não é erro de iniciante. É erro de quem ainda não levou banco ao limite.
Por que single-row inserts matam em alta frequência
Toda vez que você faz um INSERT único, o PostgreSQL paga um pedágio fixo:
- Round-trip de rede entre app e banco
- Parse e planning da query (aliviado por
pg_preparese você usar, mas ainda assim um custo) - Adquirir e liberar lock no heap e no índice
- WAL write separado pra aquele registro
- Commit individual se você não agrupou em transação
Em baixa frequência (dezenas por segundo) esse pedágio é invisível. Quando o consumer chega em alguns milhares de eventos por segundo, ele passa a ser a maior parte do trabalho do banco. O PostgreSQL gasta mais energia na cerimônia do insert do que gravando dado útil.
Um lote de 500 registros em um único INSERT paga esse pedágio uma vez. O INSERT em si fica maior, claro, mas a razão custo-fixo/trabalho-útil melhora drasticamente.
Estruturando o batch insert
Duas formas de montar um batch no PostgreSQL:
Forma 1: VALUES com múltiplas linhas
INSERT INTO events (tenant_id, event_type, payload, received_at)
VALUES
($1, $2, $3, $4),
($5, $6, $7, $8),
($9, $10, $11, $12);
Simples, legível, funciona. Desvantagem: se você precisa parametrizar 500 linhas com 4 colunas cada, são 2000 placeholders. O driver do cliente começa a reclamar, e o limite máximo de parâmetros do PostgreSQL é 65.535. Viável pra batches médios, mas não é a forma mais limpa.
Forma 2: UNNEST de arrays
INSERT INTO events (tenant_id, event_type, payload, received_at)
SELECT * FROM unnest(
$1::uuid[],
$2::text[],
$3::jsonb[],
$4::timestamptz[]
);
Aqui você passa 4 parâmetros, independente do tamanho do batch — cada um é um array. O driver serializa tudo em uma única chamada. É mais eficiente pra batches grandes e é a forma que a gente preferiu na refatoração.
Em Go, usando pgx, fica assim:
type Event struct {
EventID uuid.UUID
TenantID uuid.UUID
Type string
Payload map[string]any
ReceivedAt time.Time
}
func InsertEvents(ctx context.Context, db DBTX, events []Event) error {
if len(events) == 0 {
return nil
}
tenantIDs := make([]uuid.UUID, len(events))
types := make([]string, len(events))
payloads := make([]string, len(events))
receivedAts := make([]time.Time, len(events))
for i, e := range events {
b, err := json.Marshal(e.Payload)
if err != nil {
return fmt.Errorf("marshal payload event %d: %w", i, err)
}
tenantIDs[i] = e.TenantID
types[i] = e.Type
payloads[i] = string(b)
receivedAts[i] = e.ReceivedAt
}
_, err := db.Exec(ctx, `
INSERT INTO events (tenant_id, event_type, payload, received_at)
SELECT tenant_id, event_type, payload::jsonb, received_at
FROM unnest($1::uuid[], $2::text[], $3::text[], $4::timestamptz[])
AS u(tenant_id, event_type, payload, received_at)
`, tenantIDs, types, payloads, receivedAts)
if err != nil {
return fmt.Errorf("bulk insert events: %w", err)
}
return nil
}
Três detalhes que valem comentar. Primeiro, DBTX é uma interface mínima que aceita *pgx.Conn, *pgxpool.Pool e pgx.Tx, você passa qualquer um sem mudar a assinatura, e testar a função com transação fica trivial. Segundo, o cast payload::jsonb no SELECT: array de jsonb direto no pgx ainda dá fricção de encoding em algumas versões, então passar JSON como text[] e converter no SELECT funciona em qualquer setup, sem registrar tipo custom. Terceiro, o guard de len(events) == 0 evita uma query desnecessária e uma mensagem de erro pouco amigável do pgx em array vazio.
ON CONFLICT: DO NOTHING vs DO UPDATE
Quando o consumer pode receber eventos duplicados (e numa fila à-la-SQS com at-least-once, sempre pode), você precisa decidir o que fazer em colisão de chave única.
DO NOTHING — ignora silenciosamente:
INSERT INTO events (event_id, tenant_id, payload)
VALUES ($1, $2, $3)
ON CONFLICT (event_id) DO NOTHING;
Uso: quando o dado mais novo não vale mais que o mais velho. Eventos imutáveis, logs append-only, eventos idempotentes. Na maioria dos consumers de fila, é isso que você quer.
DO UPDATE — faz upsert:
INSERT INTO events (event_id, name, updated_at)
VALUES ($1, $2, now())
ON CONFLICT (event_id) DO UPDATE
SET name = EXCLUDED.name,
updated_at = EXCLUDED.updated_at
WHERE events.updated_at < EXCLUDED.updated_at;
Uso: quando o registro mais novo sobrepõe o antigo. Note a cláusula WHERE na ponta, é o que garante que um evento atrasado não sobrescreva um evento mais recente que já chegou antes. Sem isso, você cria inconsistência temporal.
O EXCLUDED é uma pseudo-tabela que representa a linha que tentou entrar no INSERT. Fundamental pra diferenciar “o que está no banco” de “o que eu estou tentando gravar”.
Armadilha: ON CONFLICT em batch com duplicatas dentro do próprio batch
Essa pegou a gente de surpresa. Em um batch de 500 eventos, o consumer pode ter 2 ou 3 com a mesma chave (a fila entregou duplicatas no mesmo pull). O ON CONFLICT só age contra o que já está no heap, dentro do batch, ele não ajuda. O resultado é um erro:
ERROR: ON CONFLICT DO UPDATE command cannot affect row a second time
Solução: deduplicate no cliente antes de mandar pro banco.
seen := make(map[uuid.UUID]struct{}, len(events))
deduped := make([]Event, 0, len(events))
for _, e := range events {
if _, ok := seen[e.EventID]; ok {
continue
}
seen[e.EventID] = struct{}{}
deduped = append(deduped, e)
}
Barato, defensivo, resolve.
Benchmarks
Teste sintético, mesma carga total de 10.000 eventos, mesmo schema, mesma tabela com 50M registros, Aurora PostgreSQL. Três cenários:
| Estratégia | Tempo total | Inserts/seg | CPU writer |
|---|---|---|---|
| Single-row INSERT | 47s | ~213 | 78% |
| Batch de 100 (UNNEST + ON CONFLICT) | 3.1s | ~3.225 | 41% |
| Batch de 500 (UNNEST + ON CONFLICT) | 1.4s | ~7.143 | 34% |
O salto de single-row pra batch de 100 é o que mais pesa. De 100 pra 500 o retorno é decrescente: você ganha throughput, mas aumenta o tamanho de lock e o custo de erro (se o batch falhar, 500 eventos precisam ser reprocessados).
Qual batch size escolher
Sem regra universal, mas orientação prática. Lotes de 50 a 100 são conservadores e cabem bem em tabelas com muita contenção de lock. Entre 200 e 500 fica a faixa que a maioria dos consumers acerta sem precisar pensar muito, e é o que a gente roda em produção. Acima de 1000, só se a tabela é dedicada, sem contenção, e você tolera latência de processamento maior.
Batch size é troca entre throughput e latência. Um consumer que junta 500 eventos antes de gravar tem p99 pior que um que grava de 50 em 50. Se seu caso é “realtime”, isso pesa.
Falando em latência: nem mesmo o Sol é realtime. Se ele “sumir” agora, a gente só perceberia daqui a 8 minutos e 20 segundos, que é o tempo que a luz leva pra cruzar os 150 milhões de quilômetros até a Terra. E não é só a luz. Pela relatividade geral, o efeito gravitacional também viaja na velocidade da luz, então a Terra continuaria seguindo a órbita atual nesses mesmos 8 minutos antes de “sentir” o sumiço e sair em linha reta.
A moral pro nosso problema é a mesma. A única coisa instantânea em qualquer sistema é a parte que cabe num único ciclo de CPU. Tudo que cruza barreira, rede, disco ou escala, paga latência. Quando você projeta um consumer pra batch de 500 em vez de single-row, está aceitando explicitamente o que sistemas distribuídos te impõem implicitamente. Realtime, no sentido estrito, é uma promessa que nem a física faz.
Lições aprendidas
- Nunca nasça em single-row. Qualquer consumer de fila deveria ter batch desde o dia um. É mais código, mas é o código certo.
- Dedup no cliente antes do batch.
ON CONFLICTnão ajuda contra duplicatas internas ao batch. - Escolha conscientemente DO NOTHING vs DO UPDATE. Os dois são corretos, mas pra problemas diferentes. Se você está em dúvida,
DO NOTHINGé o default mais seguro. - Na cláusula de UPDATE, proteja contra out-of-order. Inclua um
WHEREque compara timestamp. Sem isso, evento atrasado sobrescreve evento recente, e você vai descobrir isso da pior forma. - Benchmark no seu ambiente. Os números acima servem pra ordem de grandeza. Tempo absoluto depende de schema, índices, concorrência e instância.
DO NOTHING ou DO UPDATE como default no seu time? Tenho visto muito reflexo de sempre fazer upsert e pouca análise da semântica antes da escolha. Curioso pra saber se outras pessoas se incomodam com isso também.