4x mais entrega no mesmo mês: 30 dias dentro do Claude Code
O que importa não é USD 8.069 em tokens. É comprimir quatro meses de roadmap em um.
Introdução
Em 30 dias dentro do Claude Code, entreguei o equivalente a quatro meses de roadmap.
Não é métrica de IDE. É auto-observação calibrada por anos no mesmo conjunto de projetos. O que normalmente levaria 8 meses, coube em 2.
A maior parte desse roadmap aconteceu dentro da Harmo, infraestrutura Drive-to-Store que opera +60 mil lojas, processa +10 milhões de pesquisas e +300 mil avaliações por mês. Esse é o terreno em que esses 30 dias foram medidos.
Pra calibrar o tamanho do uso: rodei o equivalente a USD 8.069 em tokens nesses 30 dias, pagando um plano fixo de assinatura. Esse número não é a tese. É dimensão, ajuda a entender quanto a ferramenta esteve no fluxo. O que conta é o que saiu do outro lado.
Como cheguei nesses números
O Claude Code persiste cada sessão em ~/.claude/projects/<encoded-cwd>/<session-uuid>.jsonl. Cada linha é um evento estruturado: mensagem do humano, resposta do assistant, tool call, tool result. No caso do assistant, vem com contagem de tokens por categoria (input, output, cache write, cache read) e identificação do modelo usado.
Escrevi um script Python pequeno que soma sessões, turnos humanos, respostas, tokens por categoria e estima custo equivalente em USD usando a tabela pública da Anthropic. Roda local, sem mandar nada pra fora, com sanitização automática de credenciais antes de gravar relatório. Detalhes no apêndice.
Rodei nas duas máquinas que uso ativamente (desktop e notebook) e somei. Isso só funciona porque mantenho Claude Code sincronizado entre elas (com a pegadinha das memórias path-encoded resolvida), setup que detalhei em Sincronizando Claude Code entre máquinas.
O que saiu desses 30 dias
Em ordem de impacto, e citando só o que pode ir publicamente:
- Diagnóstico e ações ao vivo de uma crise de performance no Aurora PostgreSQL da Harmo (CPU 90% sustentada, 18 índices mortos, write amplification gratuita), com runbook documentado para o próximo incidente.
- Refator de consumer single-row para batch insert com
ON CONFLICTnum pipeline crítico da Harmo, levando o gargalo de 47 segundos para 1,4 segundo em 10 mil eventos. Eliminou uma classe inteira de incidentes futuros. - Avanços no produto principal da Harmo equivalentes a meses do roadmap normal. Não dá para detalhar publicamente, mas é a maior parte do ×4 que abriu esse post. Inclui evolução da FloraAI (plataforma de chat conversacional com LLM, MCP, tools, etc), a camada de inteligência transversal que atravessa todos os planos da plataforma.
- Várias contribuições com comunidade tech.
- Mais de 10 reports internos + Gestão estratégica do nosso cluster EKS.
- Reforma da infraestrutura de SEO, analytics e privacidade do próprio blog rifeli.dev: canonical e Open Graph dinâmicos, JSON-LD Article, banner LGPD, política de privacidade. Coisa que estava em backlog há meses, fechada numa sessão.
- Um slash command custom no Claude Code (
/save-session) e o script de análise (claude-code-stats.py) que gerou os próprios números desse post (vai pra outro artigo falando sobre ele). - O clawtop, meu primeiro open source de verdade: dashboard TUI multi-host pra acompanhar uso da subscription Claude, com daemon em cada máquina e renderização centralizada num servidor de casa. Vai virar post próprio mais adiante na série \o/.
Nem tudo isso “veio do Claude Code”. Mas todos vieram mais rápido porque ele estava aberto no segundo monitor o tempo todo. No final, cada commit precisa carregar uma assinatura né.
Sobre nosso EKS
A espinha dorsal da Plataforma Harmo é um cluster Kubernetes gerenciado na AWS (EKS). São cerca de 90 microsserviços rodando em torno de 250 pods, a maior parte sobre instâncias ARM/Graviton, escolha que nos dá melhor relação custo por desempenho. Em vez de manter um parque fixo de servidores, usamos Karpenter para provisionar e consolidar nós automaticamente, de modo que a capacidade acompanha a carga minuto a minuto. Isso sustenta o volume de processamento da operação, na casa de entenas de milhares de avaliações e milhões de pesquisas por mês, mantendo a conta de infraestrutura sob controle.
Contribuições no período:
- 1407 commits.
- 189 PRs envolvidos no período.
- 50 code reviews em 40 dias, espalhados em 16 repos. 64 PRs onde participei comentando.
- 46+ repos diferentes tocados.
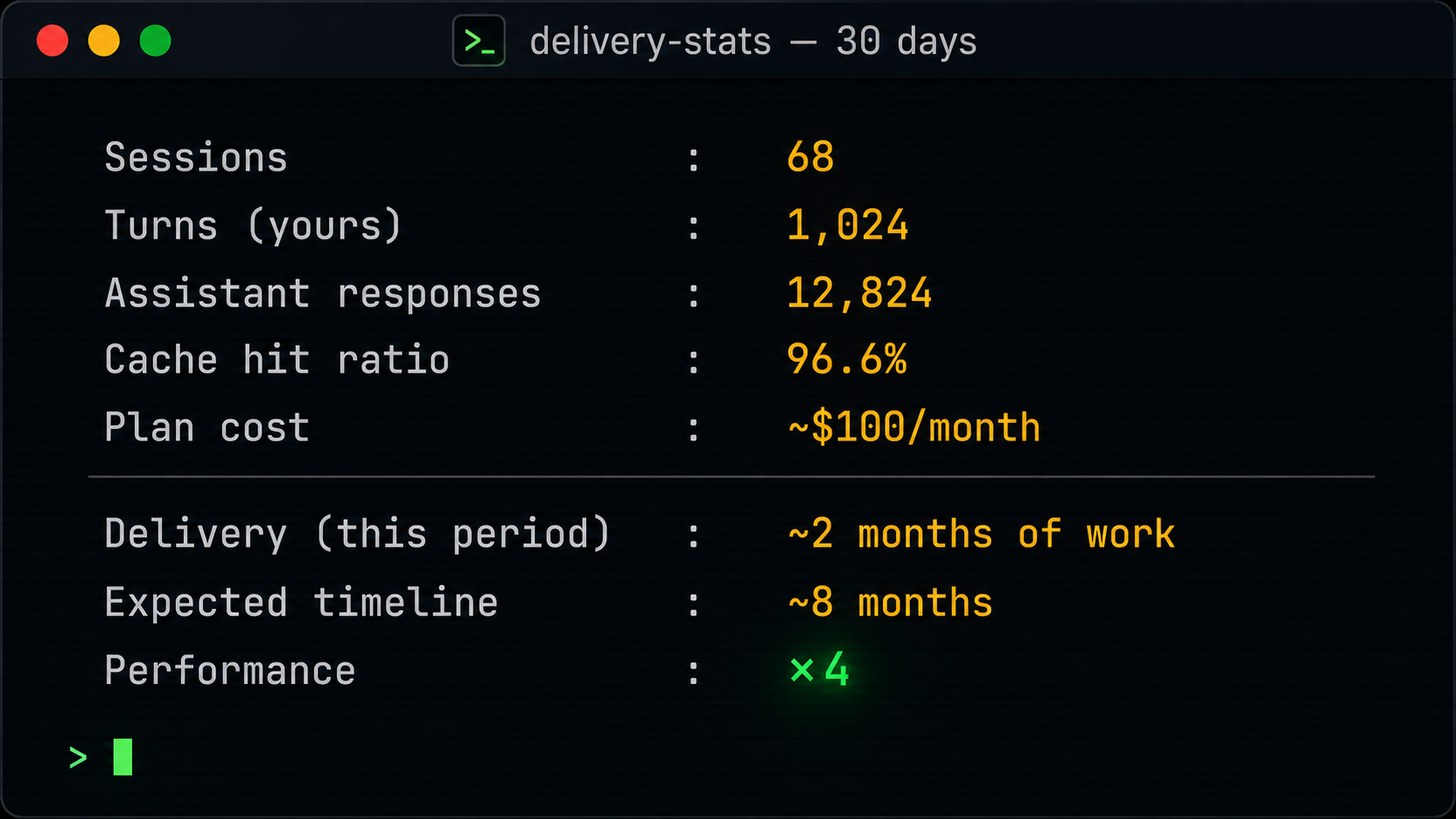
Anatomia do uso
68 sessões em 30 dias. 1.024 turnos humanos. 12.824 respostas do assistant. Em média, 12 respostas para cada coisa que eu digito. Bash domina como ferramenta usada (3.956 chamadas combinadas), seguido de Read (1.072) e Edit (969). Cache hit ratio de 96,6%.
Mediana de turnos humanos por sessão é baixa: 4 a 6. 52% das sessões são one-shot (≤ 4 turnos), 20% são ping-pong (> 10 turnos). A maioria das interações é cirúrgica, não conversa. Encomendo coisas. Quando preciso conversar, é em sessões de debug profundo, e essas pagam a fatura sozinhas.
A sessão mais cara do mês teve 152 turnos, 59 horas de relógio e custo equivalente de USD 1.741. Foi diagnóstico de incidente que destravou uma feature da Harmo em rota direta com o cliente. Em momentos assim, dimensão de uso vira diferencial de produto.
Por que isso comprime tempo
O número que mais explica o ×4 não é leverage de preço. É a razão 1.024 turnos meus contra 12.824 respostas do assistant. Cada coisa que digito vira, em média, 12 etapas executadas para mim: leitura de arquivo, escrita, busca, decisão, execução de bash, novo prompt para si mesmo. Bash domina como ferramenta porque a maior parte do trabalho técnico real é orquestração de comandos, não geração de prosa.
Não é “ChatGPT na linha de comando”. É um orquestrador que recebe intenção e devolve cadeia de ações. Compressão de tempo vem dessa relação de leverage por turno, repetida ao longo de horas, repetida ao longo de semanas. No fim do mês, sobra uma diferença de patamar entre o que eu teria feito sozinho e o que entreguei.
Toquei em 13 projetos diferentes
Oito com sessões reais. Os três que dominaram: a plataforma core da Harmo (mais de 70 microservices, +10 milhões de pesquisas e +300 mil avaliações por mês, em mais de 60 mil lojas), um motor de NLP da camada FloraAI da Harmo (que transforma voz de cliente em decisão operacional), e um repositório pessoal (esse blog). Contextos absurdamente diferentes em stack, domínio, vocabulário e decisões de arquitetura.
Variedade de stack e domínio que normalmente quebraria a coerência de qualquer assistente; o Claude Code carrega isso sem que eu reapresente o projeto a cada nova sessão. Pico de horário fica entre 12h-15h e 18h-21h (de manhã, geralmente em reuniões e análises estratégicas), com cauda longa até depois das 23h. Quarta-feira é o dia mais ativo. Usei a ferramenta em cerca de 70% dos dias do mês.
O que mudou no meu fluxo
Três coisas, sem ordem de importância.
A primeira foi começar a usar a ferramenta sem culpa de “isso vale o token?”. Plano fixo, custo marginal por uso adicional é zero, mas o instinto de “paga por chamada” de eras anteriores levou uns dias para sair.
A segunda foi virar default ter Claude Code aberto no segundo monitor. Não como assistente eventual, mas como ambiente de trabalho. A fronteira de “isso eu faço, isso eu delego” se move sem decisão consciente. Você se pega delegando algo que no mês passado teria escrito à mão.
A terceira foi escrever ferramentaria em cima da ferramenta. Construí um slash command (/save-session) que destila o que vale carregar para a próxima conversa antes de fechar a sessão. Sem isso, contexto entre conversas virava arquivo morto. Esse vira tema de um post próprio mais adiante na série.
Fechamento
O número que importa não é USD 8.069 em tokens. Nem 80x de leverage sobre o que pagaria via API. É que comprimi cerca de quatro meses de roadmap em um.
A pergunta certa para quem avalia Claude Code não é “quanto custa por hora de uso”, nem “quanto economiza em tokens”. É “quanto avança o produto enquanto a equipe inteira vai dormir”.
Apêndice: o script
O script Python que usei está em .claude/scripts/claude-code-stats.py. Lê ~/.claude/projects/ localmente, soma os últimos 30 dias (configurável), sanitiza credenciais detectadas em prompts e exporta markdown + JSON. Roda em Linux e macOS sem dependência externa além de Python 3.9+. Útil para rodar antes de qualquer conversa sobre “como você usa Claude Code” com o time. Os números reais costumam surpreender quem responde de cabeça.