clawtop: meu primeiro projeto open source, e por que ele não é só mais um dashboard pro Claude Code
A pergunta que me travou três dias
Construí uma ferramenta e mostrei pra um amigo. Ele olhou cinco segundos e disparou: “era só dar /usage e boa, não?”. Esse comentário me travou três dias. Não porque ele estivesse errado. Porque ele estava parcialmente certo, e eu precisava saber em que parte exatamente ele não estava, antes de seguir.
Esse post é sobre essa investigação, e sobre o que ela me deixou no fim: meu primeiro projeto open source de verdade, o clawtop. Um dashboard TUI multi-host pra acompanhar uso da subscription Claude. Sim, já existem várias ferramentas pra isso. Não, ele não é redundante com elas. Vou contar o caminho.
Como começou
Esses dias esbarrei no Clawdmeter, um projetinho muito massa ESP32 que mostra o consumo da subscription Claude num display AMOLED de duas polegadas, com sprites pixel-art do Clawd ficando mais agitados conforme você queima cota. É charmoso, é desnecessário, é o tipo de coisa que eu queria ter feito. Só que eu não tenho ESP32 sobrando, não queria pedir mais um pacote pra Aliexpress, e o que eu tenho é o cypher, meu home-server, com mais ciclos ociosos do que eu uso.
Mas tem um detalhe que ainda me incomodava antes mesmo de codar: eu uso Claude em três máquinas diferentes. Workstation principal, laptop de trabalho, eventualmente o próprio servidor pra testar coisas em GPU. Quando eu rodava /usage numa, via só o que aquela máquina sabia sobre a sessão local. O total da minha conta tava esparramado em três lugares, e nenhuma das ferramentas que olhei resolvia isso sem eu copiar o credencial OAuth pra um lugar central.
A primeira versão do clawtop nasceu pra resolver só o problema do display: rodar como TUI em vez de hardware. Aí veio a pergunta do amigo, eu fui investigar o que já existe, e percebi que o problema interessante não era o display. Era o que ele estava mostrando e em quantas máquinas ele estava vendo.
O que já existe (sendo honesto)
Antes de seguir construindo, sentei e fiz a lista do que o ecossistema open source já tem em 2026.
O ccusage é o padrão de facto. CLI em Node, parseia os mesmos arquivos JSONL que ficam em ~/.claude/projects e cospe relatórios bonitos por projeto, modelo, sessão, dia. Roda on-demand. Se você quer um snapshot rápido no terminal numa máquina só, ele é melhor do que qualquer coisa que eu vá construir.
O Claude-Code-Usage-Monitor do Maciek é o mais perto do que eu queria fazer: TUI Python rodando sempre ligada, com previsão de burn rate baseada em ML. A diferença é que ele assume que tudo roda na mesma máquina onde estão os transcripts.
O ccflare faz dashboard web com gráficos interativos, browser-based. O claude-usage é outra variação local com gráficos e estimativa de custos. E o Clawdmeter, claro, faz o display físico.
Lendo tudo isso, ficou claro que duas coisas ninguém estava cobrindo, ou estavam cobrindo mal: agregação multi-máquina e o modelo de segurança onde o credencial fica numa máquina diferente da que renderiza o dashboard. Esses dois pontos juntos viraram a razão de existir do clawtop. Tudo o mais é commodity.
A arquitetura, e por que ela tem duas pontas
O OAuth do Claude Pro/Max vive em ~/.claude/.credentials.json na máquina onde você roda o CLI. Esse arquivo é o portão da conta: se vaza, o atacante usa tua subscription até o token expirar. Toda ferramenta que vi assume que o consumidor desse arquivo e o renderizador do dashboard rodam no mesmo lugar. Pra quem trabalha em laptop e olha o dashboard nesse mesmo laptop, isso não importa. Pra quem quer ver em uma máquina X, importa muito: o servidor tem tunnel Cloudflare aberto, mais superfície de ataque, mais pessoas com SSH eventual. Não dá vontade de copiar o credencial pra lá.
Então o clawtop divide o sistema em duas peças. O daemon, chamado clawtopd, roda em cada máquina onde o credencial existe. Ele faz duas coisas a cada minuto: chama a API da Anthropic com Haiku e max_tokens: 1 pra ler os headers de rate limit do response, e varre os transcripts locais em ~/.claude/projects/**/*.jsonl agregando token por projeto, por modelo, por hora e por dia. O resultado vira um JSON pequeno que ele empurra pro servidor de visualização via SSH, escrita atômica via mkdir -p && cat > tmp && mv. Sem porta exposta, sem endpoint custom, sem autenticação pra eu errar. O TUI, chamado clawtop, roda no servidor dentro de um tmux, lê todos os JSONs da pasta e renderiza o merge.
┌──────────────┐ ┌──────────────────┐
│ laptop │──clawtopd──┐ │ cypher (server) │
│ │ │ │ │
│ ~/.claude/ │ │ │ /var/lib/ │
│ .credentials │ │ ssh push │ clawtop/ │
└──────────────┘ ├────atomic──▶│ laptop.json │
│ │ omen.json │
┌──────────────┐ │ │ workpc.json │
│ omen │──clawtopd──┤ │ │ │
└──────────────┘ │ │ ▼ │
│ │ clawtop (TUI) │
┌──────────────┐ │ │ inside tmux │
│ workpc │──clawtopd──┘ └──────────────────┘
└──────────────┘
│
│ HTTPS (1 Haiku token / min, fração de centavo / dia)
▼
api.anthropic.com
O credencial nunca sai da workstation. Se o cypher for invadido amanhã, o atacante leva JSONs com percentuais e contadores. Não leva o token. Muito menos vai conseguir acessar as demais máquinas na rede.
A parte multi-host, que é o truque inteiro
A sacada que tornou o projeto não-redundante foi perceber que o rate limit da Anthropic é por conta, não por máquina. Os três daemons rodando ao mesmo tempo veem todos o mesmo percentual de utilização nas janelas de cinco horas e sete dias. Mas o breakdown por projeto e por modelo vem dos transcripts locais e é por máquina. Cada um sabe só do que rodou ali.
A combinação é que dá o ganho. O servidor de visualização recebe três JSONs diferentes, um por máquina. Na hora de renderizar, o TUI faz merge: pega o rate limit mais fresco, soma os tokens por projeto e por modelo, soma os buckets horários e diários elemento a elemento, e o detalhe que mais me deixou orgulhoso: preserva atribuição por host nos projetos que aparecem em mais de uma máquina. Se eu rodo rifeli.dev tanto no omen (PC1) quanto no notebook, a linha aparece como rifeli.dev 874k no total, com uma sub-linha discreta embaixo dizendo omen 800k · notebook 74k. Em projetos single-host, a sub-linha mostra a contagem de sessões distintas no período.
Pra quem roda Claude numa máquina só, o merge de um elemento é identidade e tudo funciona igual. Pra quem roda em três, é a diferença entre ter três relatórios separados e ter uma resposta clara pra “onde foi minha cota essa semana, e em qual máquina”.
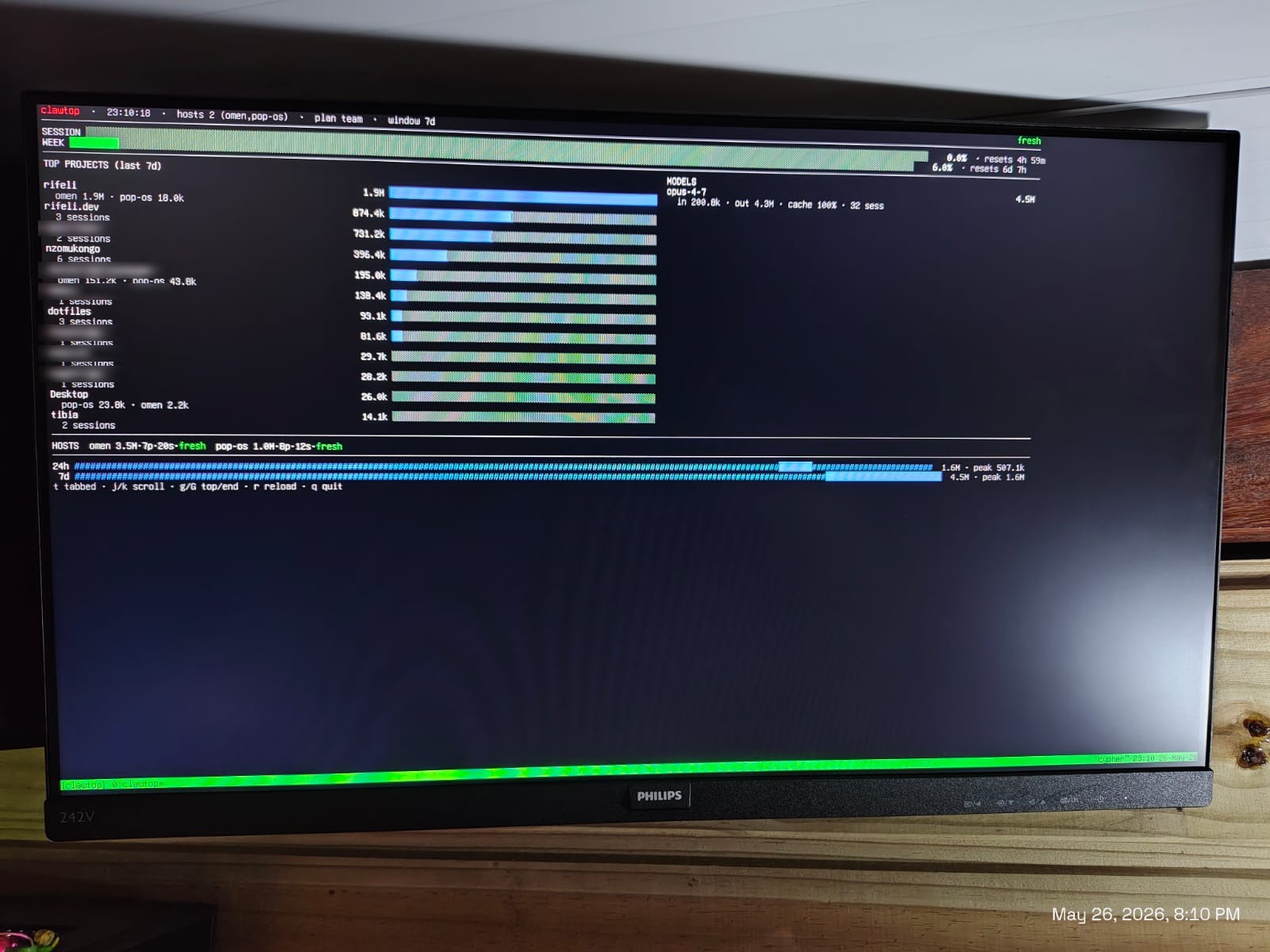
Clawtop rodando no meu home-server
O que o dashboard mostra hoje
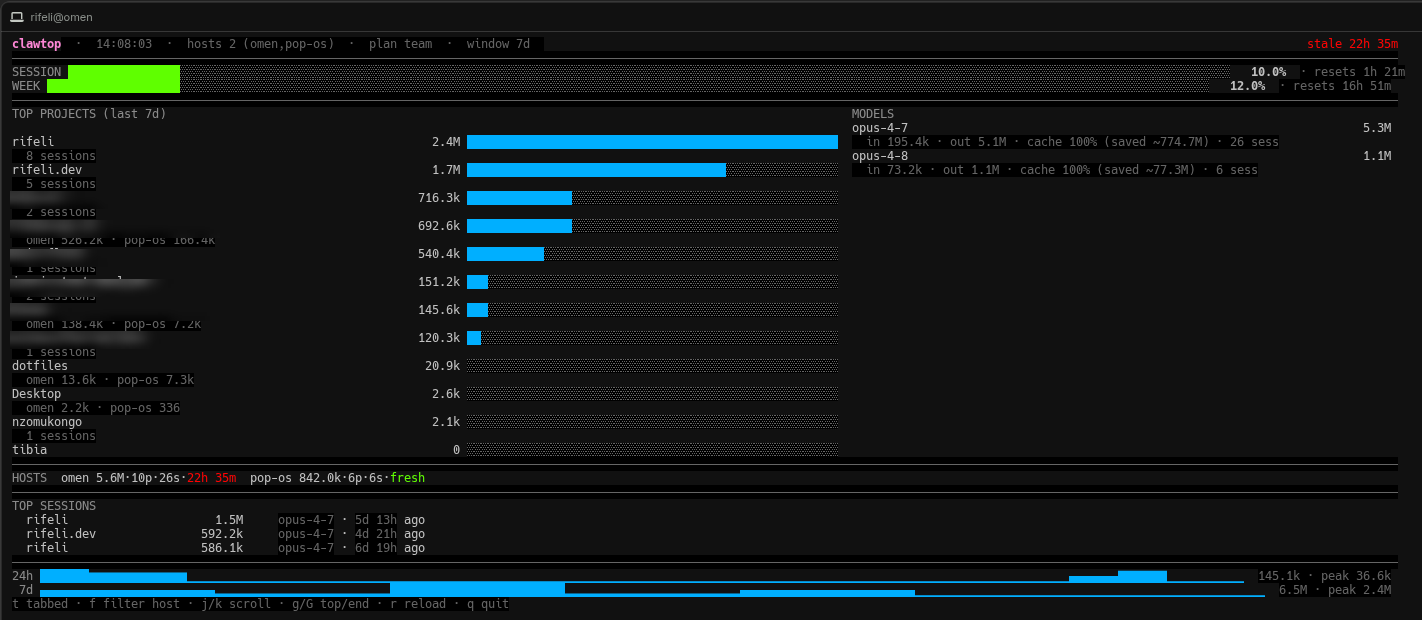
Depois de várias iterações respondendo perguntas reais de uso, o TUI tem seis abas ou, quando o terminal é grande o suficiente, um modo dashboard denso que mostra tudo numa tela só. As perguntas que ele responde:
Limits: percentual usado das janelas de cinco horas e sete dias, com countdown pro reset. A partir do v0.8 ele também calcula a taxa de queima a partir do histórico das últimas dezenas de polls e projeta: +8.2%/h · 100% em 4h 12m · OVER! quando o ritmo atual indica que você vai bater o limite antes da janela resetar. Verde “ok”, amarelo “close”, vermelho “OVER!” quando dá merda.
Projects: os projetos que mais consumiram tokens no período, com barra relativa, total formatado, contagem de sessões e “última vez tocado” pra distinguir o que tá ativo do que é só lixo histórico dentro da janela. Quando duas ou mais máquinas contribuíram pro mesmo projeto, mostra a atribuição por host.
Models: split por modelo (Opus, Sonnet, Haiku) com input, output, cache read, cache create, taxa de cache hit em porcentagem mais o equivalente em tokens economizados, e a contagem de sessões em que cada modelo foi usado. A linha do cache hit foi a que mais me surpreendeu: meus 99% de cache hit equivalem a centenas de milhões de tokens que eu não precisei mandar de novo, e nenhuma ferramenta que eu vi torna isso visível.
Hosts: tabela com cada máquina mostrando tokens contribuídos, projetos distintos, sessions distintas, freshness do último push. Quem é o cavalo, quem é o pônei, quem morreu.
Sessions: top 10 conversas mais caras do período, com projeto, modelo, duração e quando foi a última atividade. Detecta runaway antes de virar problema.
Hourly e Daily: sparkline de 24 horas em granularidade horária, e sparkline de 7 dias em granularidade diária. Identifica padrão de uso ao longo do dia e ao longo da semana.
A tecla t alterna entre o modo tabbed e o modo dashboard denso. A tecla f cicla um filtro por host (all → omen → notebook → all), pra quando você quer focar só numa máquina. Cores das barras: vermelho/laranja/verde nas barras de limit (alto é ruim), cyan único nas barras de projeto e modelo (rank não tem semântica de bom/ruim).
As decisões que valeram a pena
A primeira foi Go nos dois lados. Pensei em Python pro daemon, é mais rápido de rabiscar. Decidi Go porque o resultado é um binário único cross-compilável que copia com scp e roda. Sem virtualenv no servidor, sem pip install, sem versão de Python pra controlar. Pra um projeto que eu quero deixar funcionando por anos, vale o boilerplate extra.
A segunda foi bubbletea pra TUI. A primeira versão eu fiz com fmt.Print e ANSI escapes na mão. Funcionou em dez minutos e era impossível de evoluir. Troquei pelo bubbletea com lipgloss e o código ficou mais curto, não maior. Cada nova tela que apareceu na evolução foi quase de graça depois que o framework estava de pé.
A terceira foi reler o credencial a cada poll. A primeira tentativa carregava o credencial no startup e implementava refresh do OAuth no próprio daemon. Implementação chata, fácil de errar, e me deixaria com duas cópias do refresh logic, a do Claude CLI e a minha. Joguei tudo fora. Hoje o daemon reabre ~/.claude/.credentials.json a cada chamada. Se o CLI refrescou, eu pego o novo. Se não, falho explicitamente e o systemd reinicia. Menos código, menos jeitos de quebrar.
A quarta foi sobre descobrir o nome real do projeto a partir dos transcripts. Os diretórios em ~/.claude/projects têm nomes tipo -home-rifeli-projects-personal-rifeli-dev, onde - codifica tanto / quanto .. Ou seja, dá pra ser tanto /home/rifeli/projects/personal/rifeli/dev quanto /home/rifeli/projects/personal/rifeli.dev. Tentei várias estratégias de heurística pra decodificar e todas erravam em alguns casos. Quase desisti. Aí olhei dentro do JSONL e vi que cada mensagem do tipo user tem um campo cwd com o path absoluto, exato. Joguei o decoder fora, passei a usar cwd como verdade. Lição: antes de inventar parser, leia o arquivo até o fim \o/.
A quinta foi preservar último valor bom em caso de falha do probe. Na primeira release multi-host, o daemon zerava os percentuais quando a Anthropic devolvia 429 ou caía momentaneamente. O dashboard piscava em zero, depois voltava no próximo poll. Bug ridículo. Hoje o daemon guarda o último probe bem-sucedido em memória; se o próximo falhar, ele reusa os valores anteriores no JSON que escreve. Resultado: dashboard não pisca, e quando você olha o log vê que houve falha mas a tela continua útil.
A sexta foi o modelo de release com GoReleaser + install.sh idempotente. Cada tag dispara cross-compile pra Linux/macOS × amd64/arm64, gera .deb e .rpm, sobe pra GitHub Releases. O install.sh baixa o binário certo, deixa as units do systemd no lugar e, a partir do v0.8, detecta quais services tão habilitados e reinicia eles sozinho. Atualizar virou um comando: sh install.sh. Esse foi puxado por um pedido direto de teste real, que é a próxima seção.
Testando como um usuário de verdade
Cortei a primeira release achando que tava pronto. Aí fui ser o primeiro usuário do meu próprio projeto, seguindo o README, e cada passo revelou alguma fricção:
O install.sh aceitava silenciosamente flag desconhecida — install.sh daemon --host=cypher comia o --host=cypher sem reclamar e o usuário pensava que tinha configurado. Corrigi pro script rejeitar argumento desconhecido com erro claro.
O alias SSH do meu cypher estava quebrado naquele dia (DNS bagunçado), e o clawtopd doctor mostrou exatamente isso: FAIL ssh cypher: Permission denied (publickey), com HINT: ssh-copy-id cypher. Eu não tinha feito ssh-copy-id depois do reinstall do servidor. Sem o doctor, eu ia perder uma hora investigando. Doctor é a coisa mais barata de implementar que mais valor entrega.
O terminal que eu uso quebrava URLs longas no paste, transformando curl ... | sh em dois comandos separados que falhavam de jeitos confusos. Documentei o workaround com git clone /tmp/c && sh /tmp/c/install.sh no INSTALL.md.
A unit do systemd do viewer tinha uma flag desatualizada (--path em vez de --dir) que eu esqueci de atualizar quando renomeei. O serviço entrava em loop de start/fail/restart silenciosamente. Foi tipo o terceiro patch release, e nada vence cargo cult: você precisa de um usuário real fazendo o caminho real pra esses bugs aparecerem.
Cada uma dessas fricções virou commit, virou release, virou nota de troubleshooting no INSTALL.md. O projeto que existe hoje tem uma forma diferente do que eu publiquei na primeira tag, e cada diferença foi puxada por um momento de “ah, isso aqui tá chato”.
O que ficou de fora, e por que
Não tem TLS entre o daemon e o servidor porque SSH já é o TLS dessa conexão. Não tem queue, não tem retry com backoff agressivo, não tem persistência local de leituras. Se uma chamada falha, eu logo, espero um minuto, tento de novo. O dado é descartável, a próxima leitura sobrescreve. Quanto menos estado, menos coisa quebra às três da manhã.
Não tem auth via API key normal porque API key normal não devolve os headers da subscription, devolve os da tier de API. Pra ler anthropic-ratelimit-unified-5h-utilization da minha conta Team, OAuth é obrigatório.
Não tem dashboard web. Pensei em hospedar uma página HTML no cypher, mas era exatamente a coisa que não dava pra fazer sem expor algo novo no tunnel Cloudflare. A TUI dentro do tmux resolve sem novos vetores de ataque.
Não tem ML burn-rate prediction. O monitor do Maciek já faz isso muito bem com ML. Meu burn rate é regressão linear simples sobre os últimos polls — funciona o suficiente pra avisar “vai bater limite antes de resetar” sem complicar o código. Se você quer projeção sofisticada, use a ferramenta dele junto.
Não tem suporte a Windows. Linux e macOS por enquanto. Adicionar Windows não é difícil tecnicamente (é só compilar) mas demanda testar o caminho do credencial e do tmux equivalente, e eu não uso Windows. Issue aberta pra quem quiser contribuir.
O JSON que voa
{
"schema": 3,
"machine": "omen",
"ts": 1716688320,
"session": { "pct": 31.0, "reset_at": 1716700000 },
"week": { "pct": 5.0, "reset_at": 1717100000 },
"limit": "allowed",
"subscription": "team",
"window": "7d",
"sessions": 20,
"by_project": [
{ "name": "rifeli", "path": "/home/rifeli/projects/personal/rifeli",
"in": 12345, "out": 1900000, "cache_read": 45000000, "cache_create": 1400000,
"sessions": 5, "last_at": 1716685200 }
],
"by_model": [
{ "model": "claude-opus-4-7",
"in": 200800, "out": 4300000, "cache_read": 462500000, "cache_create": 14600000,
"sessions": 32 }
],
"hourly_24h": [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 107835, 7436, 0, 0, 0, 0, 0, 0, 178055],
"daily_7d": [120000, 250000, 80000, 400000, 600000, 1100000, 1300000],
"top_sessions": [
{ "id": "abc-...", "project": "rifeli", "model": "claude-opus-4-7",
"in": 186931, "out": 966588, "started_at": 1716680000, "last_at": 1716688000 }
]
}
Um a cinco kilobytes por máquina, schema versionado, sem nada sensível. Viewers antigos ignoram campos desconhecidos, viewers novos default-zero os que não vieram. Forward-compat barato.
Por que publicar mesmo já tendo alternativa
Esse é meu primeiro projeto open source de verdade, e a pergunta “isso já existe” me travou três dias antes de eu entender que ela está mal formulada. A pergunta certa é: “isso resolve um problema específico que as alternativas não resolvem para um conjunto de pessoas”. Se a resposta for sim, mesmo que o conjunto seja pequeno, vale publicar. Se a resposta for não, faça issue no projeto existente pedindo a feature.
No meu caso: tem gente que roda Claude em mais de uma máquina, e tem gente que se incomoda em copiar credencial pra servidor. Esses dois conjuntos somados não são o mundo, mas existem. E a forma de descobrir se existem mesmo é publicar e ver se chega issue ou PR. Eu vou descobrir junto com vocês.
Como rodar
Quando estiver na máquina que tem Claude rodando:
curl -fsSL https://raw.githubusercontent.com/leonardorifeli/clawtop/main/install.sh | sh
clawtopd doctor # confere creds, anthropic, destino
systemctl --user enable --now clawtopd-local
clawtop --dir=~/.local/share/clawtop
Se o terminal quebrar a URL no paste (alguns terminais fazem), troca por git clone https://github.com/leonardorifeli/clawtop /tmp/c && sh /tmp/c/install.sh.
Pra setup multi-host com viewer separado, o passo a passo completo está em deploy/INSTALL.md. Cerca de mil linhas de Go no total, MIT, PR aberto a quem quiser melhorar.
Créditos
Sem o Hermann Bjorgvin e o Clawdmeter eu não saberia que a Anthropic expõe esses headers via OAuth. Sem o ryoppippi e o ccusage eu provavelmente teria parado na pergunta do amigo. Construir em cima de prior art é fazer parte da conversa, não substituir.